使用 Huggingface DataSets 设置 Zhihu 数据
我们希望将 知乎的数据 注入Phi-3-mini 中。
第一步是导入知乎的 KOL 数据。
注意: 请在 datasets 文件夹中创建您的笔记本 (download_hf_zhihu_datasets.ipynb)。
0. 确认您的环境
- 将
<YOUR_DATASET_DIR>替换为datasets文件夹。
pip install datasets -U
pip install transformers -U
cd datasets/
huggingface-cli download --repo-type dataset --resume-download wangrui6/Zhihu-KOL --local-dir <YOUR_DATASET_DIR>
在您的本地机器上打开 VSCODE
- 安装
vscode ssh 插件,如下所示:
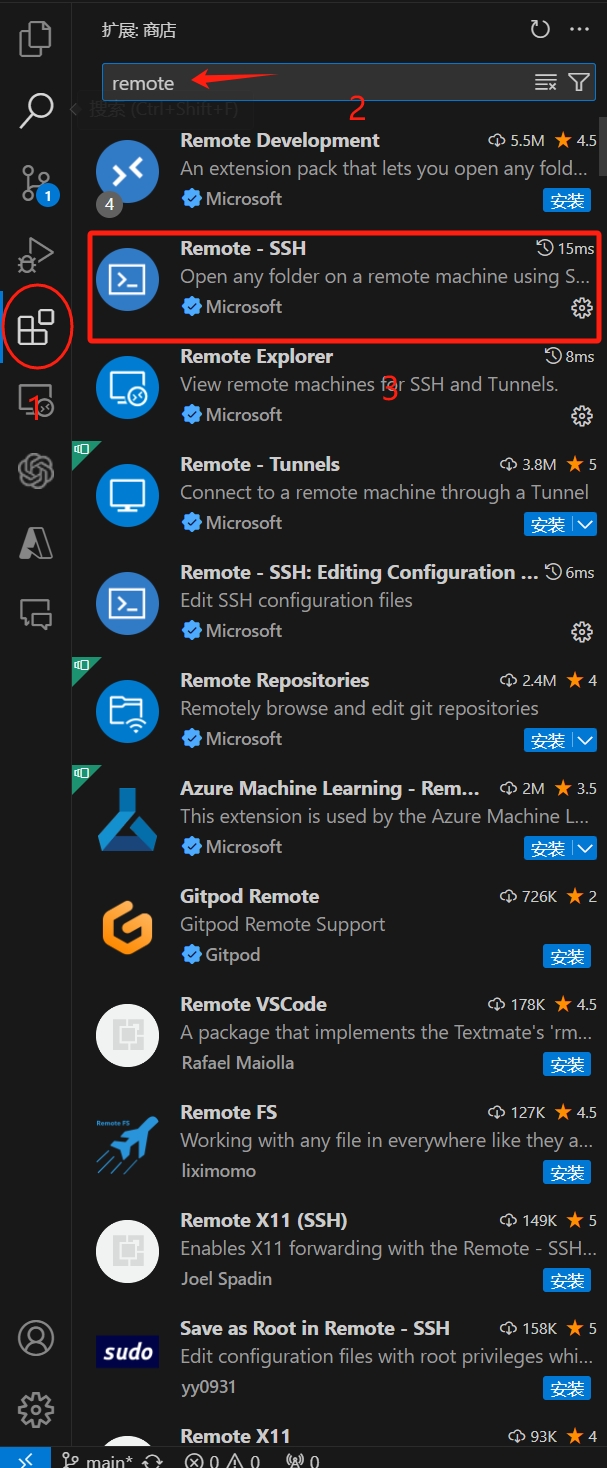
- 通过 SSH 插件远程连接到服务器。
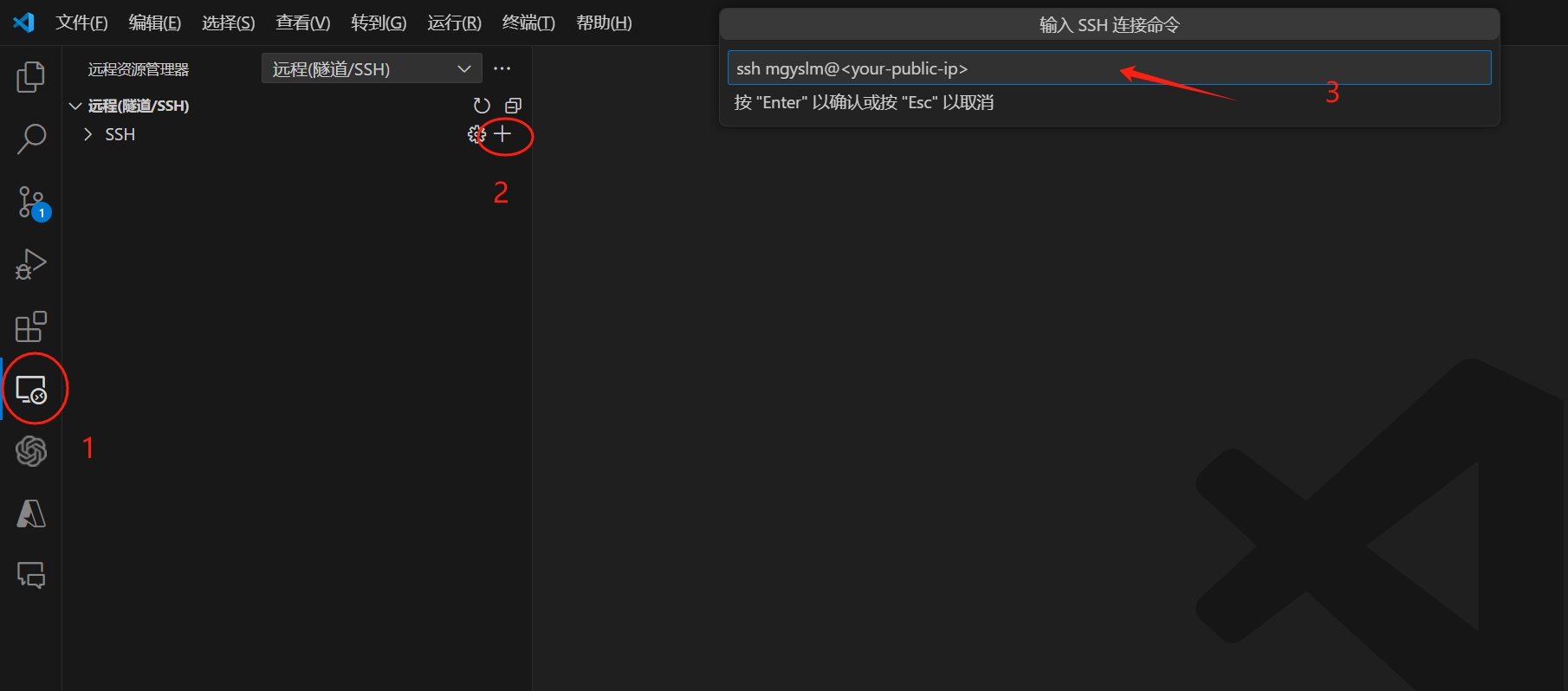
- 点击
文件->打开目录-> 选择zhihu并点击确认图标。
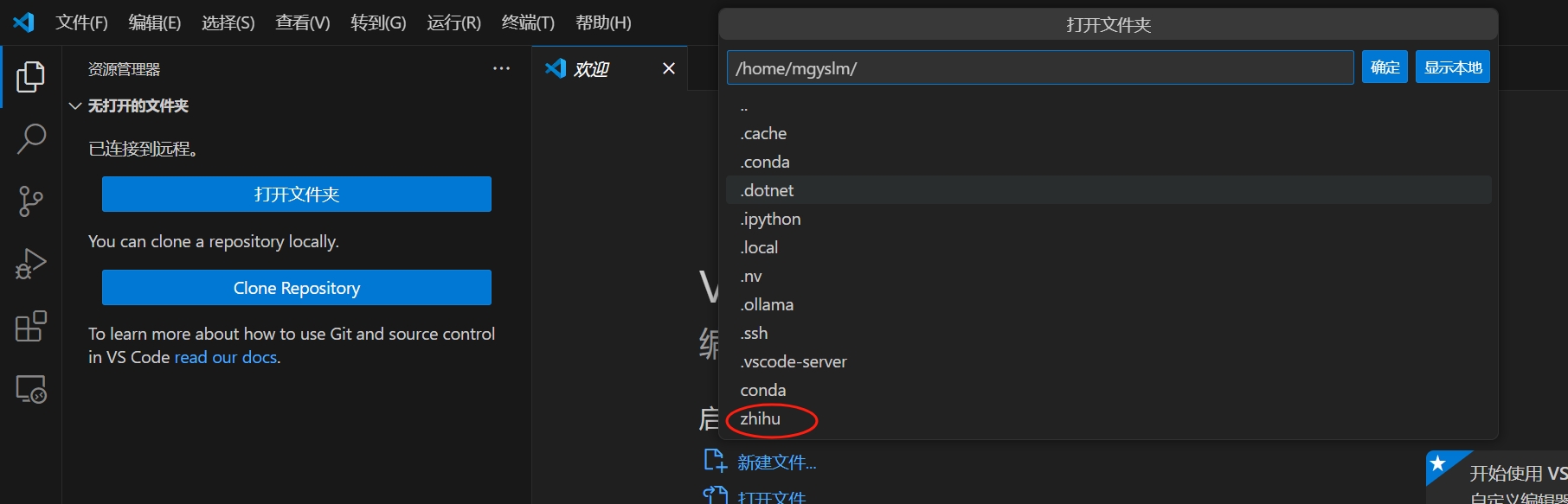
- 导航到
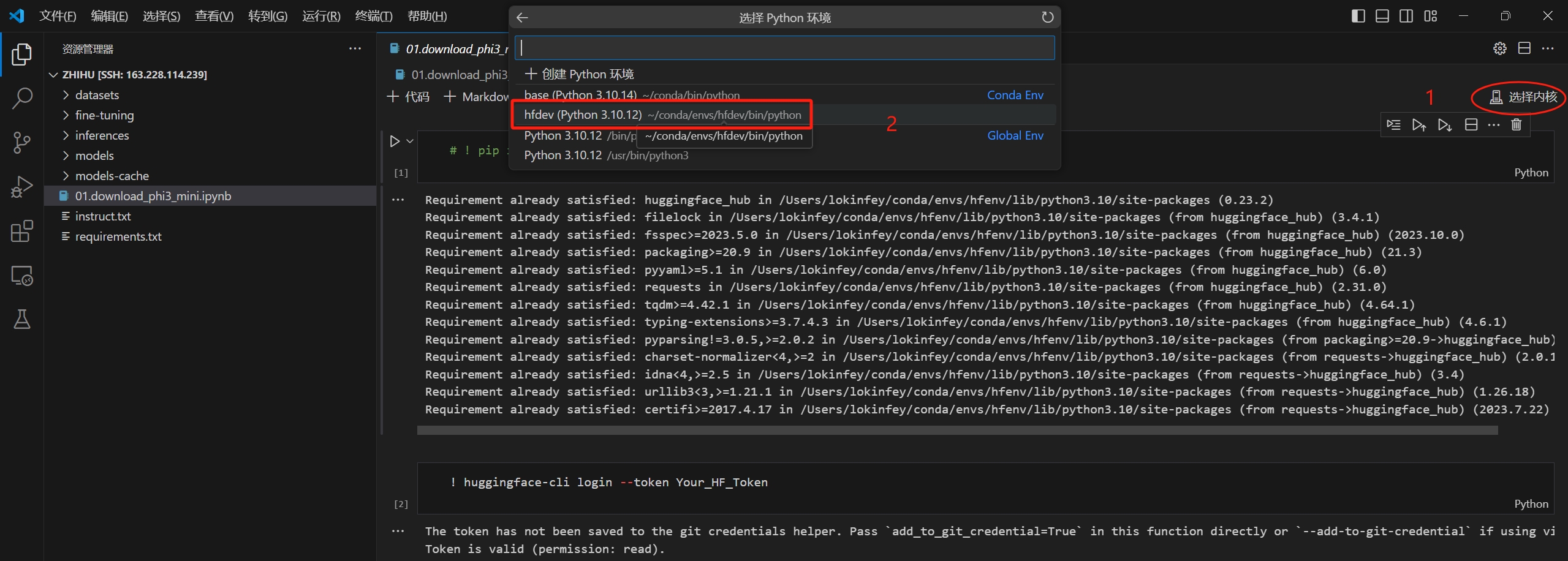
01.download_phi3_mini.ipynb文件,并在右上角选择选择内核,选择hfdev (python 3.10.12)。
以下是您提供的将数据加载到 CSV 并保存为 JSON 格式的代码段的中文翻译和解释:
1. 将数据加载到 CSV 并保存为 JSON
from datasets import load_dataset
# 加载数据集
dataset = load_dataset('<YOUR_DATASET_DIR>')
# 由于这是实验室环境,所以从 Zhihu-KOL 中取出 2000 条数据
dataset['train'].take(2000).to_csv('zhihu_dataset_train.csv')
# 打开 CSV 文件和 JSON 文件
csvfile = open('zhihu_dataset_train.csv', 'r', encoding="utf8")
jsonfile = open('zhihu_dataset_train.json', 'w',encoding="utf8")
# 定义 CSV 文件的字段名
fieldnames = ("INSTRUCTION","RESPONSE","SOURCE","METADATA")
import csv
import json
# 使用 csv.DictReader 读取 CSV 文件
reader = csv.DictReader(csvfile, fieldnames)
i = 0
for row in reader:
if i > 0:
print(row)
try:
# 将每行数据转换为 JSON 格式并写入 JSON 文件
json.dump(row, jsonfile, ensure_ascii=False)
jsonfile.write('\n')
i += 1
except ValueError:
continue
if i == 0:
i += 1
2. 清理你的数据
data = []
with open('zhihu_dataset_train.json', 'r',encoding="utf8") as file:
for line in file:
try:
data.append(json.loads(line))
except ValueError:
continue
3. 保存你的数据
import json
with open('datasets.json', 'w',encoding="utf8") as f:
for i in range(len(data)):
if i >0:
json.dump(data[i], f, ensure_ascii=False)
f.write('\n')
以下是您提供的完成数据加载后的指南的中文翻译:
恭喜!
您的数据已成功加载。
接下来,您需要通过 Microsoft Olive 配置您的数据和相关算法 E2E_LoRA&QLoRA_Config_With_Olive_CN。