Use Microsoft Olive to architect your projects
If an enterprise wants to have its own industry vertical model, it needs to start with data, fine-tuning, and deployment. In the previous content, we introduced the content of Microsoft Olive, and we now complete a more detailed introduction based on the work of E2E.
Microsoft Olive Config
If you want to know about the configuration of Microsoft Olive, please visit Fine Tuning with Microsoft Olive
Note To stay up to date, install Microsoft Olive using
pip install git+https://github.com/microsoft/Olive -U
Running Microsoft Olive in Local Compute
LoRA
This sample is use local compute,local datasets , add olive.config in fine-tuning folder
{
"input_model":{
"type": "PyTorchModel",
"config": {
"hf_config": {
"model_name": "../models/microsoft/Phi-3-mini-4k-instruct",
"task": "text-generation",
"from_pretrained_args": {
"trust_remote_code": true
}
}
}
},
"systems": {
"local_system": {
"type": "LocalSystem",
"config": {
"accelerators": [
{
"device": "GPU",
"execution_providers": [
"CUDAExecutionProvider"
]
}
]
}
}
},
"data_configs": [
{
"name": "dataset_default_train",
"type": "HuggingfaceContainer",
"params_config": {
"data_name": "json",
"data_files":"../datasets/datasets.json",
"split": "train",
"component_kwargs": {
"pre_process_data": {
"dataset_type": "corpus",
"text_cols": [
"INSTRUCTION",
"RESPONSE",
"SOURCE"
],
"text_template": "<|user|>\n{INSTRUCTION}<|end|>\n<|assistant|>\n{RESPONSE}\n( source : {SOURCE})<|end|>",
"corpus_strategy": "join",
"source_max_len": 2048,
"pad_to_max_len": false,
"use_attention_mask": false
}
}
}
}
],
"passes": {
"lora": {
"type": "LoRA",
"config": {
"target_modules": [
"o_proj",
"qkv_proj"
],
"double_quant": true,
"lora_r": 64,
"lora_alpha": 64,
"lora_dropout": 0.1,
"train_data_config": "dataset_default_train",
"eval_dataset_size": 0.3,
"training_args": {
"seed": 0,
"data_seed": 42,
"per_device_train_batch_size": 1,
"per_device_eval_batch_size": 1,
"gradient_accumulation_steps": 4,
"gradient_checkpointing": false,
"learning_rate": 0.0001,
"num_train_epochs": 5,
"max_steps": 10,
"logging_steps": 10,
"evaluation_strategy": "steps",
"eval_steps": 187,
"group_by_length": true,
"adam_beta2": 0.999,
"max_grad_norm": 0.3
}
}
},
"merge_adapter_weights": {
"type": "MergeAdapterWeights"
},
"builder": {
"type": "ModelBuilder",
"config": {
"precision": "int4"
}
}
},
"engine": {
"log_severity_level": 0,
"host": "local_system",
"target": "local_system",
"search_strategy": false,
"cache_dir": "cache",
"output_dir" : "../models-cache/microsoft/phi3-mini-finetuned"
}
}
QLoRA
{
"input_model":{
"type": "PyTorchModel",
"config": {
"hf_config": {
"model_name": "../models/microsoft/Phi-3-mini-4k-instruct",
"task": "text-generation",
"from_pretrained_args": {
"trust_remote_code": true
}
}
}
},
"systems": {
"local_system": {
"type": "LocalSystem",
"config": {
"accelerators": [
{
"device": "GPU",
"execution_providers": [
"CUDAExecutionProvider"
]
}
]
}
}
},
"data_configs": [
{
"name": "dataset_default_train",
"type": "HuggingfaceContainer",
"params_config": {
"data_name": "json",
"data_files":"../datasets/datasets.json",
"split": "train",
"component_kwargs": {
"pre_process_data": {
"dataset_type": "corpus",
"text_cols": [
"INSTRUCTION",
"RESPONSE",
"SOURCE"
],
"text_template": "<|user|>\n{INSTRUCTION}<|end|>\n<|assistant|>\n{RESPONSE}\n( source : {SOURCE})<|end|>",
"corpus_strategy": "join",
"source_max_len": 2048,
"pad_to_max_len": false,
"use_attention_mask": false
}
}
}
}
],
"passes": {
"qlora": {
"type": "QLoRA",
"config": {
"compute_dtype": "bfloat16",
"quant_type": "nf4",
"double_quant": true,
"lora_r": 64,
"lora_alpha": 64,
"lora_dropout": 0.1,
"train_data_config": "dataset_default_train",
"eval_dataset_size": 0.3,
"training_args": {
"seed": 0,
"data_seed": 42,
"per_device_train_batch_size": 1,
"per_device_eval_batch_size": 1,
"gradient_accumulation_steps": 4,
"gradient_checkpointing": false,
"learning_rate": 0.0001,
"num_train_epochs": 3,
"max_steps": 10,
"logging_steps": 10,
"evaluation_strategy": "steps",
"eval_steps": 187,
"group_by_length": true,
"adam_beta2": 0.999,
"max_grad_norm": 0.3
}
}
},
"merge_adapter_weights": {
"type": "MergeAdapterWeights"
},
"builder": {
"type": "ModelBuilder",
"config": {
"precision": "int4"
}
}
},
"engine": {
"log_severity_level": 0,
"host": "local_system",
"target": "local_system",
"search_strategy": false,
"cache_dir": "cache",
"output_dir" : "../models-cache/microsoft/phi3-mini-finetuned"
}
}
Notice
-
If you use QLoRA, the quantization conversion of ONNXRuntime-genai is not supported for the time being.
-
It should be pointed out here that you can set the above steps according to your own needs. It is not necessary to completely configure the above these steps. Depending on your needs, you can directly use the steps of the algorithm without fine-tuning. Finally you need to configure the relevant engines
Running Microsoft Olive
After you finished Microsoft Olive , you need to run this command in terminal
olive run --config olive-config.json
Notice
- When Microsoft Olive is executed, each step can be placed in the cache. We can view the results of the relevant steps by viewing the fine-tuning directory.
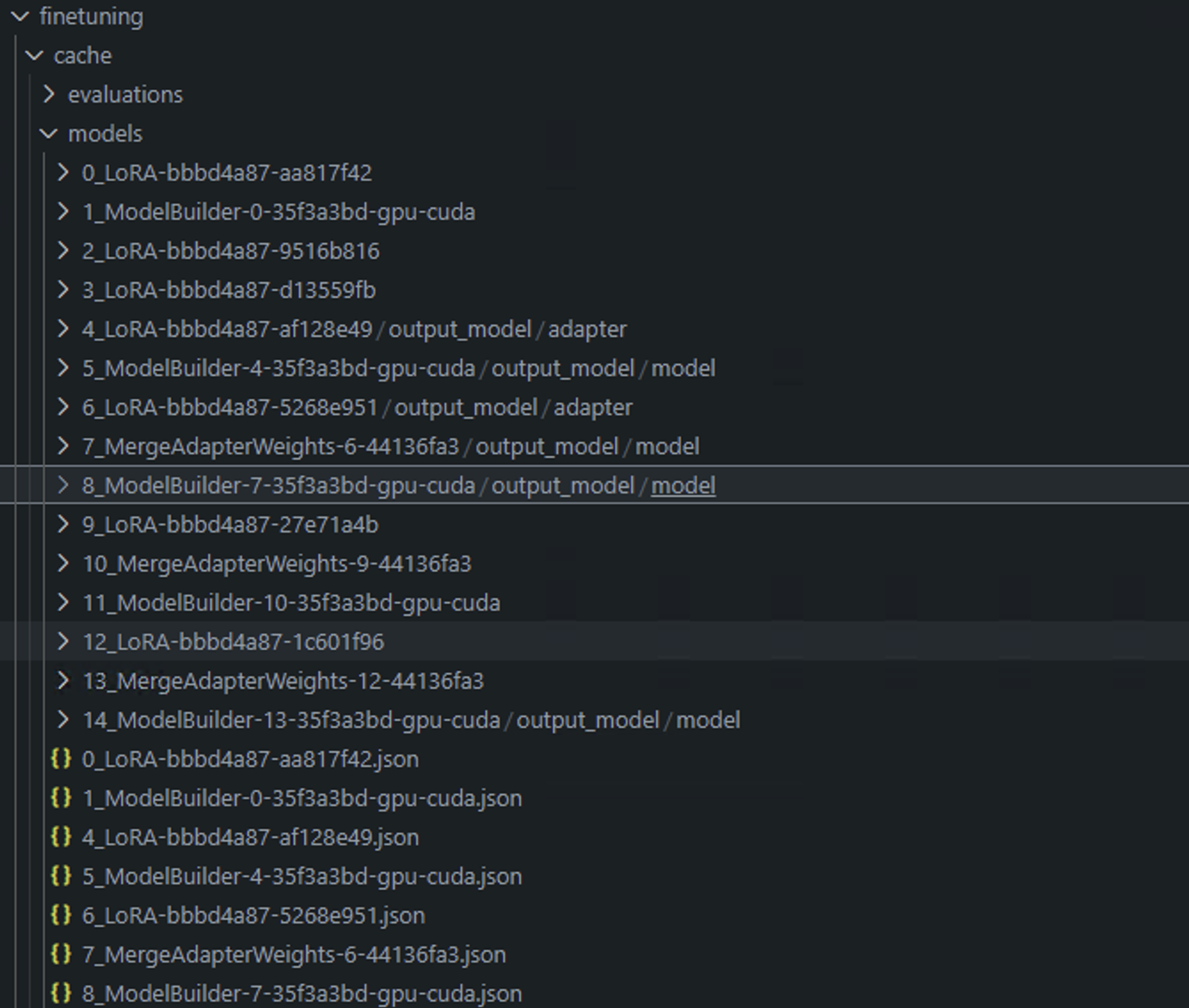
-
We provide both LoRA and QLoRA here, and you can set them according to your needs.
-
The recommended running environment is WSL / Ubuntu 22.04+.
-
Why choose ORT? Because ORT can be deployed on edge devices, Inference is implemented in the ORT environment.
